

Se lancer dans la Data Science peut être accablant, en particulier si l’on prend en compte la variété de concepts et de techniques qu’un Data Scientist doit maîtriser pour pouvoir faire son travail efficacement. Même le terme “Data Science” peut être quelque peu nébuleux et, à mesure que le champ gagne en popularité, il semble perdre sa définition. Pour aider les nouveaux venus sur le terrain à rester au top du jargon et de la terminologie du secteur, nous avons rassemblé le vocabulaire de la Data Science.
Nous espérons que ce glossaire vous servira de référence rapide lorsque vous travaillez sur un projet, ou que vous lisez un article, et que vous ne vous souvenez plus très bien de ce que signifie “ETL”.
Fondamentaux
Voici quelques concepts de base qu’il est utile de comprendre lorsqu’on se lance dans la science des données. Bien que vous n’ayez probablement pas à travailler avec tous les concepts mentionnés ici, connaître la signification de ces termes vous aidera à lire des articles. Cela vous aidera aussi a avoir le vocabulaire de la Data Science pour discuter de sujets avec d’autres personnes.
Algorithmes
Un algorithme est un ensemble d’instructions que nous donnons à un ordinateur pour qu’il puisse prendre des valeurs et les manipuler sous une forme utilisable. Cela peut être aussi simple que de rechercher et de supprimer toutes les virgules d’un paragraphe ou aussi complexe que de résoudre une équation aux dérivées partielles.
Back End
Le back-end est constitué de tout le code et de la technologie qui fonctionne en coulisse pour alimenter le frontal avec des informations utiles. Cela inclut les bases de données, les serveurs, les procédures d’authentification et bien plus encore. Vous pouvez penser à l’arrière-plan comme à l’ossature, à la plomberie et au câblage d’un appartement.
Big Data
Le Big Data est un terme qui souffre d’être trop large pour être utile. Il est plus utile de lire «autant de données qu’il est nécessaire de prendre des mesures minutieuses pour éviter des exécutions de scripts d’une semaine». Les mégadonnées sont davantage des stratégies et des outils qui aident les ordinateurs à effectuer des analyses complexes de très grandes (supérieure à 1 TB) ensembles de données. Les problèmes auxquels nous devons faire face avec le Big Data sont classés par les 4 V: volume, variété, véracité et vélocité.
Classification
La classification est un problème d’apprentissage automatique supervisé. Il traite de la catégorisation d’un point de données en fonction de sa similarité avec d’autres points de données. Vous prenez un ensemble de données dans lequel chaque élément possède déjà une catégorie et examinez les caractéristiques communes de chaque élément. Vous utilisez ensuite ces traits communs comme guide pour la catégorie que le nouvel élément pourrait avoir.
Base de données
Aussi simplement que possible, il s’agit d’un espace de stockage pour les données. Nous utilisons principalement des bases de données avec un système de gestion de base de données (SGBD), comme PostgreSQL ou MySQL. Ce sont des applications informatiques qui nous permettent d’interagir avec une base de données pour collecter et analyser les informations qu’il contient.
Entrepôt de données
Un entrepôt de données est un système utilisé pour analyser rapidement les tendances de l’entreprise à l’aide de données provenant de nombreuses sources. Ils sont conçus pour permettre aux utilisateurs de répondre facilement à des questions statistiques importantes sans doctorat. en architecture de base de données.
Front End
Le Front End comprend tout ce qu’un client ou un utilisateur peut voir et avec lequel il interagit directement. Cela inclut les tableaux de bord de données, les pages Web et les formulaires.
Algorithmes Flous
Algorithmes utilisant la logique floue pour réduire le temps d’exécution d’un script. Les algorithmes flous ont tendance à être moins précis que ceux utilisant la logique booléenne. Ils ont également tendance à être plus rapides et la vitesse de calcul est parfois supérieure à la perte de précision.
Logique floue
Une abstraction de la logique booléenne qui substitue l’habituel Vrai et Faux et une plage de valeurs comprise entre 0 et 1. En d’autres termes, la logique floue permet des énoncés du type “un peu vrai” ou “la plupart du temps faux”.
Algorithmes Gloutons
Un algorithme gourmand divisera un problème en une série d’étapes. Il cherchera ensuite la meilleure solution possible à chaque étape, dans le but de trouver la meilleure solution globale disponible. Un bon exemple est l’algorithme de Dijkstra, qui recherche le chemin le plus court possible dans un graphique.
Machine Learning
Processus par lequel un ordinateur utilise un algorithme pour comprendre un ensemble de données, puis effectue des prédictions en fonction de sa compréhension. Il existe de nombreux types de techniques d’apprentissage automatique. la plupart sont classées comme techniques supervisées ou non supervisées.
Overfitting
La sur-adaptation survient lorsqu’un modèle prend en compte trop d’informations. C’est comme demander à une personne de lire une phrase en regardant une page à travers un microscope. Les schémas qui permettent la compréhension se perdent dans le bruit.
Régression
La régression est un autre problème d’apprentissage automatique supervisé. Il se concentre sur la façon dont une valeur cible change lorsque d’autres valeurs d’un jeu de données changent. Les problèmes de régression concernent généralement des variables continues, telles que la manière dont la superficie et l’emplacement affectent le prix d’une maison.
Statistique vs. Statistiques
Statistiques (pluriel) est l’ensemble des outils et méthodes utilisés pour analyser un ensemble de données. Une statistique (singulier) est une valeur que nous calculons ou déduisons à partir de données. Nous obtenons la médiane (une statistique) d’un ensemble de nombres en utilisant des techniques du domaine de la statistique.
Apprentissage et test
Cela fait partie du flux de travail d’apprentissage automatique. Lorsque vous créez un modèle prédictif, vous lui fournissez d’abord un ensemble de données d’apprentissage qui lui permet de mieux comprendre. Ensuite, vous transmettez au modèle un ensemble de tests dans lequel il applique sa compréhension et tente de prédire une valeur cible.
Underfitting
Il y a sous-équipement lorsque vous n’offrez pas suffisamment d’informations à un modèle. Un exemple de sous-ajustement serait de demander à quelqu’un de représenter graphiquement le changement de température sur une journée et de ne lui donner que le haut et le bas. Au lieu de la courbe lisse attendue, vous ne disposez que de suffisamment d’informations pour tracer une ligne droite.
Domaines du Data

Visualisation des données
Au fur et à mesure que les entreprises se concentrent davantage sur les données, de nouvelles opportunités s’offrent à des personnes de divers niveaux de compétences pour qu’elles fassent partie de la communauté des données. Ce sont quelques-uns des domaines de spécialisation existant dans le domaine de la science des données.
Connaitre ces domaine vous permettra d’approfondir votre jargon et vocabulaire de la Data Science
Intelligence artificielle (IA)
Une discipline qui implique la recherche et le développement de machines conscientes de leur environnement. La plupart travaillent dans A.I. se concentre sur l’utilisation de la conscience de la machine pour résoudre des problèmes ou accomplir une tâche. Au cas où vous ne le sauriez pas, A.I. est déjà là: pensez aux voitures autonomes, aux robots chirurgiens et aux méchants de votre jeu vidéo préféré.
Business Intelligence (BI)
Similaire à l’analyse de données, mais plus étroitement centré sur les métriques commerciales. L’aspect technique de la BI consiste à apprendre à utiliser efficacement un logiciel pour générer des rapports et identifier les tendances importantes. C’est descriptif plutôt que prédictif.
L’analyse des données
Cette discipline est le petit frère de la science des données. L’analyse des données est davantage axée sur la réponse aux questions sur le présent et le passé. Il utilise des statistiques moins complexes et essaie généralement d’identifier les modèles qui peuvent améliorer une organisation.
Ingénierie de données (Data Engineering)
L’ingénierie des données concerne le back-end. Ce sont ces personnes qui construisent des systèmes qui facilitent l’analyse des scientifiques de données. Dans les équipes plus petites, un scientifique de données peut également être un ingénieur de données. Dans les groupes plus importants, les ingénieurs peuvent uniquement se concentrer sur l’accélération de l’analyse et la conservation des données bien organisées et faciles d’accès.
Journalisme de données (Data Journalism)
Cette discipline consiste à raconter des histoires intéressantes et importantes avec une approche centrée sur les données. Cela s’est fait naturellement avec plus d’informations devenant disponibles sous forme de données. Une histoire peut concerner des données ou être informée par des données. Il existe un manuel complet si vous souhaitez en savoir plus.
Science des données (Data Science)
Compte tenu de l’expansion rapide du domaine, la définition de la science des données peut être difficile à cerner. En gros, il s’agit de l’utilisation de données et de statistiques avancées pour faire des prévisions. La science des données est également axée sur la création d’une compréhension entre des données en désordre et disparates. Le «problème» abordé par un scientifique diffère considérablement d’un employeur à l’autre.
Visualisation de données
L’art de communiquer visuellement des données significatives. Cela peut impliquer des infographies, des tracés traditionnels ou même des tableaux de bord complets. Nicholas Felton est un pionnier dans ce domaine et Edward Tufte a littéralement écrit le livre.
Analyse quantitative:
Ce domaine est fortement axé sur l’utilisation d’algorithmes pour se démarquer dans le secteur financier. Ces algorithmes recommandent ou prennent des décisions de trading basées sur une énorme quantité de données, souvent de l’ordre de la picoseconde. Les analystes quantitatifs sont souvent appelés “quants”.
Outils statistiques
Il existe un certain nombre de statistiques utilisées par les professionnels des données pour raisonner et communiquer des informations sur leurs données. Voici quelques-uns des outils statistiques les plus élémentaires et les plus essentiels pour vous aider à démarrer.
Corrélation
La corrélation est la mesure de la mesure dans laquelle un ensemble de valeurs dépend d’un autre. Si les valeurs augmentent ensemble, elles sont positivement corrélées. Si l’une des valeurs d’un ensemble augmente à mesure que l’autre diminue, elles sont négativement corrélées. Il n’y a pas de corrélation lorsqu’un changement dans un ensemble n’a rien à voir avec un changement dans l’autre.
Moyenne (moyenne, valeur attendue)
Un calcul qui nous donne une idée d’une valeur “typique” pour un groupe de nombres. La moyenne est la somme d’une liste de valeurs divisée par le nombre de valeurs de cette liste. Il peut être trompeur d’être utilisé seul et, en pratique, nous utilisons la moyenne avec d’autres valeurs statistiques pour obtenir l’intuition de nos données.
Médian
Dans un ensemble de valeurs répertoriées dans l’ordre, la médiane est la valeur située au milieu. Nous utilisons souvent la médiane et la moyenne pour déterminer s’il existe des valeurs inhabituellement élevées ou basses dans l’ensemble. Ceci est un indice précoce pour explorer les valeurs aberrantes.
Normaliser
Un ensemble de données est dit normalisé lorsque toutes les valeurs ont été ajustées pour tomber dans une plage commune. Nous normalisons les ensembles de données pour rendre les comparaisons plus faciles et plus significatives. Par exemple, prendre les classements de films de plusieurs sites Web et les ajuster afin qu’ils tombent tous sur une échelle de 0 à 100.
Valeur aberrante
Une valeur aberrante est un point de données considéré comme extrêmement éloigné des autres points. Elles sont généralement le résultat de cas exceptionnels ou d’erreurs de mesure et doivent toujours être examinées tôt dans un flux de travail d’analyse de données.
Échantillon
L’échantillon est la collection de points de données auxquels nous avons accès. Nous utilisons l’échantillon pour tirer des conclusions sur une population plus importante. Par exemple, un sondage politique utilise un échantillon de 1 000 citoyens grecs pour inférer les opinions de l’ensemble de la Grèce.
Déviation standard
L’écart type d’un ensemble de valeurs nous aide à comprendre l’étendue de ces valeurs. Cette statistique est plus utile que la variance car elle est exprimée dans les mêmes unités que les valeurs elles-mêmes. Mathématiquement, l’écart-type est la racine carrée de la variance d’un ensemble. Il est souvent représenté par le symbole grec sigma, σ.
Signification statistique
Un résultat est statistiquement significatif lorsque nous jugeons que cela n’a probablement pas été le fruit du hasard. Il est très utilisé dans les enquêtes et les études statistiques, bien qu’il ne soit pas toujours une indication de la valeur pratique. Les détails mathématiques d’importance statistique dépassent le cadre de cet article, mais une explication plus complète est disponible ici.
Statistiques sommaires
Les statistiques récapitulatives sont les mesures que nous utilisons pour communiquer des informations sur nos données de manière simple. Des exemples de statistiques sommaires sont la moyenne, la médiane et l’écart type.
Des séries chronologiques (Temporelles)
Une série chronologique est un ensemble de données ordonnées par chaque point de données. Pensez aux cours boursiers sur un mois ou à la température tout au long de la journée.
Résiduelle (erreur)
Le résidu est une mesure de la différence entre une valeur réelle et une valeur statistique calculée à partir de l’ensemble de données. Donc, étant donné la prévision selon laquelle il fera 20 degrés Fahrenheit demain à midi, quand il sera midi et qu’il ne s’agit que de 18 degrés, nous avons une erreur de 2 degrés. Cela est souvent utilisé de manière interchangeable avec le terme “erreur”, même si, techniquement, l’erreur est une valeur purement théorique.
Variance
La variance d’un ensemble de valeurs mesure l’étendue de ces valeurs. Mathématiquement, il s’agit de la différence moyenne entre les valeurs individuelles et la moyenne de l’ensemble des valeurs. La racine carrée de la variance pour un ensemble nous donne l’écart type, ce qui est plus intuitivement utile.
Parties d’un flux de travail
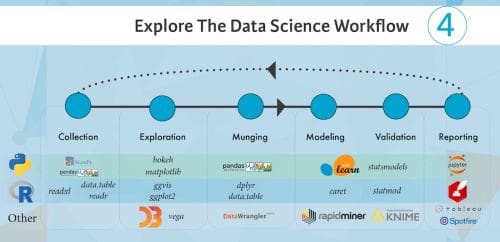
Le workflow de la Data Science
Bien que chaque flux de travail soit différent, il s’agit de certains des processus généraux que les professionnels de l’information utilisent pour obtenir des informations à partir des données.
Exploration de données
La partie du processus de science des données où un scientifique posera des questions de base qui l’aideront à comprendre le contexte d’un ensemble de données. Ce que vous apprendrez au cours de la phase d’exploration guidera plus loin une analyse plus approfondie. En outre, cela vous aide à reconnaître quand un résultat peut être surprenant et à justifier une enquête plus approfondie.
Data Mining
Processus consistant à extraire des informations exploitables d’un ensemble de données et à les utiliser à bon escient. Cela inclut tout, depuis le nettoyage et l’organisation des données; l’analyse pour trouver des modèles et des relations significatives; de communiquer ces connexions de manière à aider les décideurs à améliorer leur produit ou leur organisation.
Pipelines de données
Une collection de scripts ou de fonctions qui transmettent des données dans une série. La sortie de la première méthode devient l’entrée de la seconde. Cela continue jusqu’à ce que les données soient nettoyées et transformées de manière appropriée pour la tâche sur laquelle une équipe travaille.
Wrangling de données (Munging)
Processus consistant à prendre les données dans leur forme d’origine et à les “apprivoiser” jusqu’à ce qu’elles fonctionnent mieux dans un flux de travail ou un projet plus large. Apprivoiser signifie rendre les valeurs cohérentes avec un ensemble de données plus volumineux, remplacer ou supprimer des valeurs susceptibles d’affecter l’analyse ou les performances ultérieurement, etc. La querelle et l’attachement sont utilisées de manière interchangeable.
ETL (Extraire, Transformer, Charger)
Ce processus est essentiel pour les entrepôts de données. Il décrit les trois étapes permettant de transférer les données de nombreux endroits sous forme brute sur un écran, prêtes à être analysées. Les systèmes ETL nous sont généralement offerts par les ingénieurs en informatique et fonctionnent en coulisse.
Web Scraping
Le Web Scraping consiste à extraire des données du code source d’un site Web. Il s’agit généralement d’écrire un script qui identifiera les informations souhaitées par un utilisateur et les extraira dans un nouveau fichier pour une analyse ultérieure.
Techniques de Machine Learning
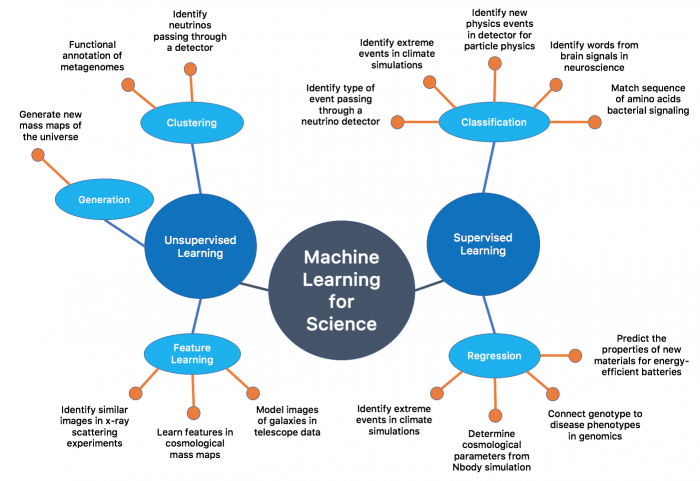
Les techniques de machines Learning.
Le domaine de l’apprentissage automatique a tellement grandi qu’il existe maintenant des postes pour les ingénieurs d’apprentissage automatique. Les termes ci-dessous offrent un large aperçu de certaines techniques courantes utilisées dans l’apprentissage automatique.
Clustering
Les techniques de regroupement tentent de collecter et de classer des ensembles de points en groupes suffisamment “proches” ou “proches” les uns des autres. La “proximité” varie selon la manière dont vous choisissez de mesurer la distance. La complexité augmente à mesure que le nombre de fonctionnalités ajoutées à un espace de problème.
Arbres de décision
Cette méthode d’apprentissage automatique utilise une série de questions ou d’observations sur un ensemble de données donné pour prédire une valeur cible. Ils ont tendance à sur-adapter les modèles à mesure que les ensembles de données deviennent volumineux. Les forêts aléatoires sont un type d’algorithme d’arbre de décision conçu pour réduire le sur-ajustement.
Deep Learning
Les modèles d’apprentissage en profondeur utilisent de très grands réseaux de neurones, appelés réseaux profonds, pour résoudre des problèmes complexes, tels que la reconnaissance faciale. Les couches d’un modèle commencent par l’identification de modèles très simples, puis par la complexité. À la fin, le réseau a une compréhension nuancée qui permet de classer ou de prédire avec précision les valeurs.
Ingénierie des fonctionnalités (Feature Engineering)
Processus consistant à prendre les connaissances que nous avons en tant qu’êtres humains et à les traduire en une valeur quantitative qu’un ordinateur peut comprendre. Par exemple, nous pouvons traduire notre compréhension visuelle de l’image d’une tasse en une représentation de l’intensité des pixels.
Sélection de fonctionnalité (Feature Selection)
Le processus d’identification des caractéristiques d’un ensemble de données sera le plus précieux lors de la construction d’un modèle. C’est particulièrement utile avec les grands ensembles de données, car utiliser moins de fonctionnalités réduira le temps et la complexité nécessaires à la formation et au test d’un modèle. Le processus commence par mesurer la pertinence de chaque caractéristique d’un ensemble de données pour prédire votre variable cible. Vous choisissez ensuite un sous-ensemble de fonctionnalités qui conduira à un modèle hautes performances.
Les réseaux de neurones
Une méthode d’apprentissage automatique très vaguement basée sur les connexions neuronales dans le cerveau. Les réseaux de neurones sont un système de noeuds connectés segmentés en couches – des couches d’entrée, de sortie et masquées. Les couches cachées (il peut y en avoir beaucoup) sont les poids lourds utilisés pour faire des prédictions. Les valeurs d’une couche sont filtrées par les connexions à la couche suivante, jusqu’à ce que le dernier ensemble de sorties soit fourni et qu’une prédiction soit effectuée.
Apprentissage supervisé
Avec les techniques d’apprentissage supervisé, le Data Scientist donne à l’ordinateur un ensemble de données bien défini. Toutes les colonnes sont étiquetées et l’ordinateur sait exactement ce qu’il recherche. Cela ressemble à un professeur qui vous remet un programme et vous dit à quoi vous attendre lors de la finale.
Apprentissage automatique non supervisé
Dans les techniques d’apprentissage non supervisées, l’ordinateur développe sa propre compréhension d’un ensemble de données non étiquetées. Les techniques de ML non supervisées recherchent des modèles dans les données et traitent souvent de la classification des éléments sur la base de traits partagés.

très utile pour comprendre vos articles