

Le data mining, également connu sous le nom d’exploration de données, est une discipline qui consiste à extraire des informations précieuses à partir de vastes ensembles de données. Dans un monde où nous sommes constamment submergés par des quantités massives de données, le data mining joue un rôle essentiel en nous permettant de découvrir des schémas cachés, des tendances et des relations significatives.
Dans la présent article, nous plongerons dans les principes de base du data mining. Nous découvrirons les concepts clés tels que le prétraitement des données, la classification, la prédiction, le regroupement et l’analyse de séquences. Nous explorerons également les applications du data mining dans des domaines tels que la santé, le marketing et la détection de fraudes.
Prêt à vous immerger dans le monde passionnant du data mining 🤔?
👉Continuez à lire pour découvrir comment exploiter le potentiel de vos données et transformer l’information en connaissances exploitables.
Les principes de base du data mining :
L’exploration de données est basée sur plusieurs principes clés, notamment :
Data mining comme processus itératif :
Tout d’abord, il s’agit d’un processus itératif qui implique l’extraction, la transformation et la visualisation des données. Ensuite, le data mining nécessite une compréhension approfondie des données disponibles et des objectifs de l’analyse. Les techniques statistiques et d’apprentissage automatique sont appliquées pour identifier des modèles significatifs, des tendances et des relations cachées
- Extraction : Collecte de données à partir de différentes sources telles que des bases de données, des fichiers CSV ou des API.
- Transformation : Nettoyage des données en éliminant les valeurs manquantes, les valeurs aberrantes et en normalisant les variables.
- Visualisation : Utilisation de graphiques, de diagrammes ou de tableaux pour représenter les données de manière compréhensible.
Data mining comme approche de sélection :
En effet, le data mining repose également sur la sélection appropriée des variables, des méthodes de prétraitement des données et des mesures d’évaluation pour garantir la validité et la fiabilité des résultats.
- Sélection des variables : Choix des variables les plus significatives pour améliorer la précision des modèles.
- Prétraitement des données : Normalisation des données numériques, encodage des variables catégorielles et gestion des valeurs manquantes.
- Mesures d’évaluation : Utilisation de mesures telles que la précision, le rappel, la précision globale pour évaluer la performance des modèles.
Data mining comme méthode d’interprétation :

Enfin, la capacité d’interpréter et de communiquer efficacement les résultats du data mining est primordiale pour en tirer des informations exploitables.
- Interprétation : Analyse des résultats pour comprendre les relations, les schémas ou les tendances découverts.
- Communication : Présentation des résultats de manière claire et concise, en utilisant des graphiques, des visualisations ou des rapports à l’aide Power bi, qui pourra vous aidez dans la creation de vos graphes et de vos rapports.
Le prétraitement des données :

Le prétraitement des données comprend aussi plusieurs sous-étapes:
-
L’élimination des valeurs manquantes :
-
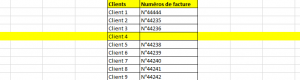
Les données manquantes 📊 peuvent être problématiques car elles peuvent fausser les résultats de l’analyse. Différentes techniques peuvent être utilisées pour gérer ces valeurs manquantes, telles que l’imputation des valeurs manquantes ou la suppression des lignes ou des colonnes contenant des valeurs manquantes excessives.
-
La détection et la gestion des valeurs aberrantes :
Les valeurs aberrantes, qui diffèrent considérablement des autres données, peuvent avoir un impact négatif sur les résultats du data mining. Il est donc important de les identifier et de décider de les supprimer, de les remplacer ou de les traiter d’une manière appropriée en fonction du contexte.
-
La normalisation ou la mise à l’échelle des variables :
Les données peuvent provenir de différentes sources avec des échelles différentes. La normalisation permet donc de mettre toutes les variables sur une même échelle, ce qui facilite la comparaison et l’analyse des données.
-
Le codage des variables catégorielles :
Les algorithmes de data mining👩🏻💻 reposent souvent basés sur des calculs mathématiques, donc il est nécessaire de représenter les variables catégorielles sous une forme numérique. Cela peut se réalisé en utilisant des techniques telles que l’encodage one-hot, qui transforme chaque catégorie en une variable binaire distincte.
-
La réduction de la dimensionnalité :
Lorsque les ensembles de données sont vastes et complexes, il peut être bénéfique de réduire le nombre de variables pour simplifier l’analyse et améliorer l’efficacité des algorithmes de data mining. Des techniques telles que l’analyse en composantes principales (PCA) ou la sélection de variables permettent de réduire la dimensionnalité des donnée .
Vous pourriez aussi aimer :
- L’analyse de données : Principes de base et méthodes populaires – BrightCape
- Critères de choix d’une formation enligne en Data (brightcape.co)
- Power BI, Excel, R et Python : Exploitez le plein potentiel de vos analyses de données – BrightCape
- Le Data Mining Vs Le Data Warehousing : quelle différence ? (brightcape.co)
