

A priori, sans avoir de connaissance sur le sujet, le machine learning peut paraître un sujet insurmontable. Il faut savoir qu’il y a deux principales branches d’algos : supervisés et non supervisés. Nous allons nous intéresser ici aux algos supervisé. La définition de Wikipédia est la suivante : L’apprentissage supervisé est une tâche d’apprentissage automatique consistant à apprendre une fonction de prédiction à partir d’exemples annotés, au contraire de l’apprentissage non supervisé. On distingue les problèmes de régression des problèmes de classement. Ainsi, on considère que les problèmes de prédiction d’une variable quantitative sont des problèmes de régression tandis que les problèmes de prédiction d’une variable qualitative sont des problèmes de classification.
Le machine Learning, ou apprentissage automatique, est une élément principal quand il s’agit d’intelligence artificielle. L’apprentissage automatique constitue une grande avancée des lors que vous voulez créer une intelligence artificielle ou tentez simplement d’obtenir un aperçu de toutes les données que vous avez collectées.
Dans cet article nous allons exposer 5 principaux algorithmes d’apprentissage supervisé.
1 – Régression linéaire
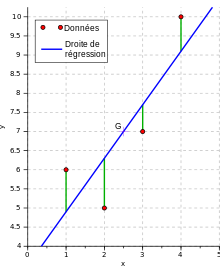
La régression linéaire est l’un des algorithmes d’apprentissage supervisé les plus populaires. Il est aussi simple et parmi les mieux compris en statistique et en apprentissage automatique.
La régression linéaire est un type d’analyse prédictive de base. Le concept général de la régression est d’étudier deux questions:
- un ensemble de variables prédictives permet-il de prédire une variable de résultat ?
- Quelles sont les variables les plus significatives et ont le plus d’impact sur la variable de résultat ?
On utilise ces estimations de régression pour expliquer les relation entre variable dépendante et une ou plusieurs variables indépendantes. La forme la plus simple de l’équation de régression avec une variable dépendante et une variable indépendante est définie par la formule y = c + b * x, avec y = variable dépendante estimé, c = constante, b = coefficient de régression et x = variable indépendante. On parle ici de Régression linéaire simple. Pour la regression linéaire multiple on écrira y = c + b * x1 +…+ n*xn avec x1 jusqu’à xn les variables indépendantes et b jusqu’à n les coefficient de regression respectifs des variables.
2 – Régression logistique
Les prédictions de régression linéaire sont des valeurs continues (températures en degrés), les prévisions de régression logistique sont des valeurs discrètes, c’est-à-dire un ensemble fini de valeurs (Vrai ou faux par exemple). La régression logistique convient mieux à la classification binaire. Par exemple, on peut considérer un ensemble de données où y = 0 ou 1, où 1 représente la classe par défaut. Pour illustrer on peut imaginer que l’on veuille prédire si il pleuvra ou non. On aura 1 pour si il pleut et 0 le cas contraire.
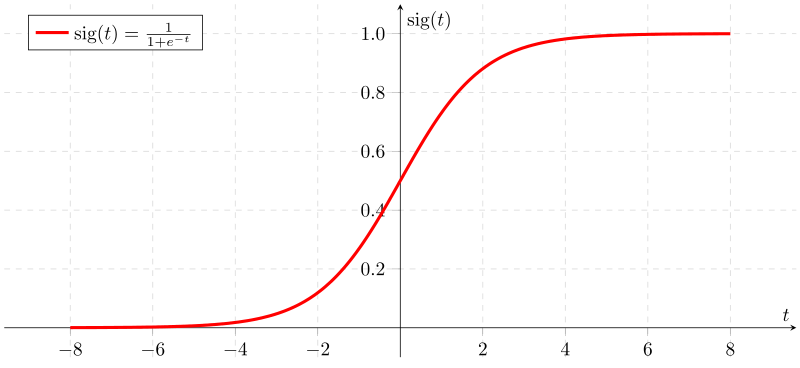
Au contraire de la régression linéaire, la régression logistique, propose le résultat sous forme de probabilités de la classe par défaut. Le résultat appartient donc à l’intervalle [0 :1]. C’est-à-dire qu’il est compris entre 0 et 1, vu qu’il s’agit d’une probabilité. La valeur y de sortie est générée par la transformation de la valeur x, à l’aide de la fonction logistique h (x) = 1 / (1 + e ^ -x). Un seuil est ensuite appliqué pour forcer cette probabilité dans une classification binaire.
3 – Arbres de classification et de régression
Les arbres de classification et de régression, aussi connus sous le nom de CART (Classification And Regression Tree), sont une forme simple d’arbres de décision. Cette structure n’utilise que des algorithmes et des structures de données. Ces arbre n’ont que deux composantes:
– Les nœuds de branchement, qui représentent une seule variable d’entrée et offrent un seul point de partage sur la variable.
– Les nœuds feuille, qui représentent les deux variables de sortie.

A l’exécution de l’algorithme par la machine, la prédiction est faite en suivant les divisions du nœud de branche jusqu’à atteindre un nœud feuille. Ce nœud feuille est la prédiction ou la sortie de la valeur de classe.
Les arbres de classification et de régression sont faciles à apprendre et à utiliser, et précis pour toute une gamme de problèmes. Celles-ci sont particulièrement rapides à mettre en œuvre car les données ne nécessitent aucune préparation particulière.
4 – K-NN
L’algorithme K-NN qui signifie k-voisins les plus proches utilise l’intégralité du data set en tant qu’entraînement, au lieu de diviser se dernier en un training et testing set.
Quand un résultat est requis pour une nouvelle instance de données, l’algorithme KNN parcourt l’intégralité du data set pour rechercher les k-instances les plus proches de la nouvelle instance ou le nombre k d’instances les plus similaires au nouvel enregistrement, puis renvoie la moyenne de les résultats ou le classe à laquelle appartient cette instance si c’est un problème de classification. L’utilisateur spécifie lui meme la valeur de k.
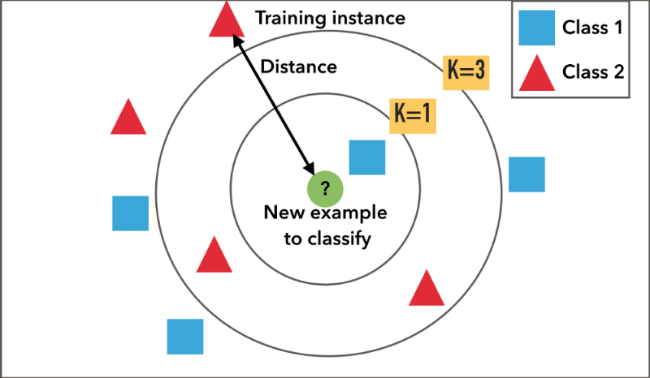
La similarité entre les instances est calculée à l’aide de mesures telles que la distance euclidienne et la distance de Hamming.
5 – Naïve Bayes Classifier
Il serait difficile et pratiquement impossible de classer manuellement une page Web, un document, un courrier électronique ou toute autre note textuelle volumineuse. C’est ici que l’algorithme d’apprentissage automatique du classificateur Naïve Bayes entre en scène. Un classificateur est une fonction qui attribue la valeur d’un élément de population à l’une des catégories disponibles. Par exemple, le filtrage du courrier indésirable est une application populaire de l’algorithme Naïve Bayes. Filtre anti-spam ici, est un classificateur qui attribue une étiquette «Spam» ou «Pas de spam» à tous les emails.
Naïve Bayes Classifier est l’une des méthodes d’apprentissage supervisé les plus populaires parmi celle utilisant les similarités, qui s’appuie sur le populaire théorème de probabilité de Bayes. En particulier pour la prédiction des maladies et la classification des documents. Il s’agit d’une classification simple de mots basée sur le théorème de probabilité de Bayes pour l’analyse subjective du contenu.
