

Dans cet article, nous allons vous exposer l’algorithme d’apprentissage par machine SVM (Support Vector Machine). Nous vous proposons une étude simple et courte, tout en gardant l’essentiel du concept. Le but étant de donner à ceux qui parmi vous débuteraient dans l’apprentissage automatique une compréhension de base des concepts clés de cet algorithme.
Support Vector Machines
Une machine à vecteurs de support, traduction littérale pour Support Vector Machine, est un algorithme d’apprentissage automatique supervisé qui peut être utilisé à des fins de classification et de régression. Les SVM sont plus généralement utilisés dans les situations de classification.
Les SVM reposent sur l’idée de trouver un hyperplan qui divise au mieux un jeu de données en deux classes, comme le montre l’image ci-dessous.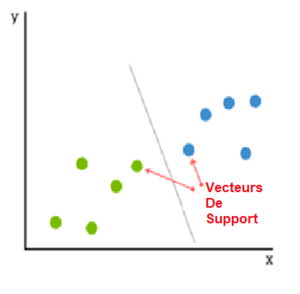
Vecteurs de support
Les vecteurs de support sont les points de données les plus proches de l’hyperplan (cf image ci-dessus). Les points d’un ensemble de données qui, s’ils étaient supprimés, modifieraient la position de l’hyperplan en division. Pour cette raison, ils peuvent être considérés comme des éléments prépondérents d’un ensemble de données.
Qu’est-ce qu’un hyperplan?
À titre d’exemple simple, pour une tâche de classification n’ayant que deux caractéristiques (cf image ci-dessus), vous pouvez concevoir un hyperplan comme une ligne séparant et classifiant linéairement un ensemble de données.
Intuitivement, plus nos points de données sont loins de l’hyperplan, plus nous sommes convaincus qu’ils ont été bien classés. Le but est donc que nos points de données soient aussi éloignés que possible de l’hyperplan, tout en restant du bon côté.
Ainsi, lorsque de nouvelles données de test sont ajoutées, quel que soit le côté de l’hyperplan qu’il atterrit, il décidera de la classe que nous lui attribuons.
Comment trouver le bon hyperplan?
On peut formuler cette question de la manière suivante: comment séparer au mieux les deux classes au sein des données?
La distance entre l’hyperplan et le point de données le plus proche de l’un des ensembles est appelée la marge. Le but est de choisir un hyperplan avec la plus grande marge possible entre l’hyperplan et n’importe quel point de l’entraînement, ce qui augmente les chances que les nouvelles données soient classées correctement.
Mais que se passe-t-il quand il n’y a pas d’hyperplan facilement determinable?
C’est là que ça peut devenir difficile. Les données sont rarement aussi propres que notre exemple simple ci-dessus. Un jeu de données ressemblera souvent plus aux boules mélangées ci-dessous, qui représentent un jeu de données linéairement non séparable.
<Pour classer un jeu de données comme celui ci-dessus, il est nécessaire de passer d’une vue 2d des données à une vue 3D. Expliquer cela est plus facile avec un autre exemple simplifié. Imaginez que nos deux séries de boules colorées ci-dessus soient assises sur une feuille et que cette feuille se soulève soudainement, projetant les boules dans les airs. Pendant que les balles sont en l’air, vous utilisez la feuille pour les séparer. Ce «soulèvement» des billes représente la mise en correspondance de données dans une dimension supérieure. Ceci est connu comme le kernelling. Vous pouvez en lire plus sur Kerneling ici.
Parce que nous sommes maintenant en trois dimensions, notre hyperplan ne peut plus être une ligne. Il doit maintenant s’agir d’un avion comme dans l’exemple ci-dessus. L’idée est que les données continueront d’être mappées dans des dimensions de plus en plus grandes jusqu’à ce qu’un hyperplan puisse être formé pour les séparer.
Avantages et inconvénients des machines à vecteurs de support
Avantages
• Sa grande précision de prédiction
• Fonctionne bien sur de plus petits data sets
• Ils peuvent être plus efficace car ils utilisent un sous-ensemble de points d’entraînement.
Les inconvénients
• Ne convient pas à des jeux de données plus volumineux, car le temps d’entraînement avec les SVM peut être long
• Moins efficace sur les jeux de données contenant du bruits et beaucoup d’outliers
Utilisations SVM
Le SVM est utilisé pour les problèmes de classification de texte telles que l’attribution de catégorie, la détection du spam ou encore l’analyse des sentiments. Ils sont également couramment utilisés pour les problèmes de reconnaissance d’image, particulièrement en reconnaissance de forme et en classification de couleur. SVM joue également un rôle essentiel dans de nombreux domaines de la reconnaissance manuscrite des symboles, tels que les services d’automatisation postale.
